MLflow consists of multiple blocks with multiple functionality which help us simplify the ML workflow. In simpler words, Mlflow will help us in various stage of our ML development and deployment.

Given below are key functionality offered by Mlflow
- MLflow Tracking
- MLflow Projects
- MLflow Models
- Model Registry
- MLflow Deployments Server for LLMs
- MLflow LLM Evaluate
MLflow Tracking
This is the real reason to use MLflow. Tracking will help us to visualize and understand how our Machine learning model is behaving.
For example: We are working on our ML/DL project with the help of multiple developers. Every developer tries to get the best accuracy out of the model. But how can we compare everyone's implementation? MLflow will help us in this situation. It will track every parameter, metric, artifact, data, and environment configuration. which will help us understand through GUI form.
In other word MLflow allows us to log and compare multiple runs of our machine learning experiments. We can easily track different configurations, hyperparameters, and outcomes.
MLflow Projects
At the core, MLflow Projects are just a convention for organizing and describing your code to let other data scientists (or automated tools) run it. Each project is simply a directory of files, or a Git repository, containing your code. MLflow can run some projects based on a convention for placing files in this directory.
I suggest to visit given link for more detail explanation -> MLflow Projects
MLflow Models
An MLflow Model is a standard format for packaging machine learning models that can be used in a variety of downstream tools—for example, real-time serving through a REST API or batch inference on Apache Spark. The format defines a convention that lets you save a model in different “flavors” that can be understood by different downstream tools.
I suggest to visit given link for more detail explanation about flavors -> flavors
Model Registry
Model Registry assists in handling different versions of models, discerning their current state, and ensuring smooth productionization. It offers a centralized model store, APIs, and UI to collaboratively manage an MLflow Model’s full lifecycle, including model lineage, versioning, aliasing, tagging, and annotations.
MLflow Deployments Server for LLMs
The MLflow Deployments Server is a powerful tool designed to streamline the usage and management of various large language model (LLM) providers, such as OpenAI and Anthropic, within an organization. It offers a high-level interface that simplifies the interaction with these services by providing a unified endpoint to handle specific LLM related requests.
A major advantage of using the MLflow Deployments Server is its centralized management of API keys. By storing these keys in one secure location, organizations can significantly enhance their security posture by minimizing the exposure of sensitive API keys throughout the system. It also helps to prevent exposing these keys within code or requiring end-users to manage keys safely.
Example
To understand MLflow web GUI. first, create conda environment.
conda create --name mlflowtest
activate envirment with
conda activate mlflowtest
install mlflow
pip install mlflow==2.4.2
I am using given below code
# The data set used in this example is from http://archive.ics.uci.edu/ml/datasets/Wine+Quality
# P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis.
# Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.
import os
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
from urllib.parse import urlparse
import mlflow
from mlflow.models.signature import infer_signature
import mlflow.sklearn
import logging
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
if __name__ == "__main__":
warnings.filterwarnings("ignore")
np.random.seed(40)
# Read the wine-quality csv file from the URL
csv_url = (
"https://raw.githubusercontent.com/mlflow/mlflow/master/tests/datasets/winequality-red.csv"
)
try:
data = pd.read_csv(csv_url, sep=";")
except Exception as e:
logger.exception(
"Unable to download training & test CSV, check your internet connection. Error: %s", e
)
# Split the data into training and test sets. (0.75, 0.25) split.
train, test = train_test_split(data)
# The predicted column is "quality" which is a scalar from [3, 9]
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5
l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5
with mlflow.start_run():
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha={:f}, l1_ratio={:f}):".format(alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
predictions = lr.predict(train_x)
signature = infer_signature(train_x, predictions)
tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme
# Model registry does not work with file store
if tracking_url_type_store != "file":
# Register the model
# There are other ways to use the Model Registry, which depends on the use case,
# please refer to the doc for more information:
# https://mlflow.org/docs/latest/model-registry.html#api-workflow
mlflow.sklearn.log_model(
lr, "model", registered_model_name="ElasticnetWineModel", signature=signature
)
else:
mlflow.sklearn.log_model(lr, "model", signature=signature)
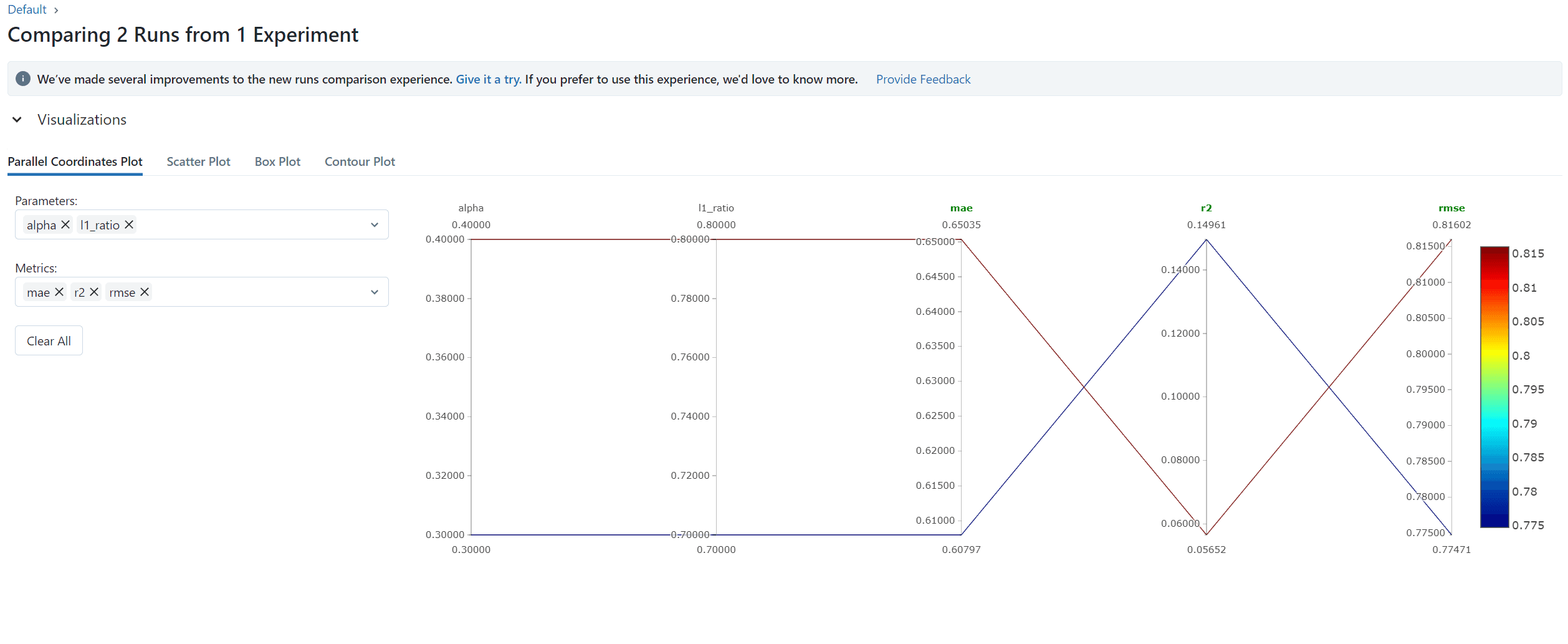
Run it with the first and second argument as alpha and l1_ratio respectively.
for first experiment run
python example.py 0.3 0.7
for second experiment run
python example.py 0.4 0.8
After running the given below command
mlflow ui
It will give us a link to visualize our model in a web application. INFO:waitress:Serving on http://127.0.0.1:5000
Currently, i am working on my local computer.
Home page of mlflow.

By selecting both experimental runs. We can select the compare button to visualize and compare our experiments on multiple diagrams.